
Existential Risk vs. Existential Opportunity: A balanced approach to AI risk


Photo 214655527 © Jakub Jirsak | Dreamstime.com
Executive summary
Artificial intelligence represents an existential opportunity – it has strong potential to improve the future of humankind drastically and broadly. AI can save, extend, and improve the lives of billions of people. AI will create new challenges and problems. Some of them may be major and perhaps frightening at the time. If we are not to stagnate as a society, we must summon the courage to vigorously advance artificial intelligence while being mindful and watchful and ready to respond and adapt to problems and risks as they arise. It is impossible to plan for all risks ahead of time. Confident claims that AI will destroy us must be acknowledged and carefully examined but considered in the context of the massive costs of relinquishing AI development and the lost existential opportunity. The most sensible way to think about safety and regulatory approaches is not the precautionary principle; it is the Proactionary Principle, or permissionless innovation.
Contents
Existential opportunity and its relationship to existential eucatastrophe and existential hope.
Existential uncertainty: Uncertainty is a better frame than risk.
Grasping the existential opportunity – the underappreciated benefits of AI.
More benefits from AI: They are just getting started.
Obstacles to AI doom: Risk equations and barriers to AI domination.
What the experts believe: Be careful with citing surveys.
Precautionary and centralized is not the way: We don’t need a Department of AI or lots of new rules.
Proactionary safety – approaches to reasonable safety measures with nine suggestions.
The current debate about AI is taking place in a culture of fear and excessive caution. The opportunities opened up by AI are being massively underappreciated. We should think about existential risk but think just as much about existential opportunity.
When you read “existential risk” what do you picture? Almost certainly, your mind fills exclusively with images of human life destroyed by an asteroid strike, AI takeover, apocalyptic climate disaster, unprecedented pandemic, or global nuclear holocaust. You don’t think of enormous and widespread increases in human longevity, wellbeing, wealth, and peace. Yet conditions that create risk invariably also create opportunity. The familiar example being from investing: By taking on risk, you also open up opportunities to gain. Another everyday example: When you exercise vigorously, you incur some risk of injury but also create an opportunity to improve your strength, endurance, and flexibility.
How much risk comes with opportunity depends on several factors including the time frame and the extent of the context. That’s why, despite sounding paradoxical, it can be risky not to take risks. If a comfortable retirement depends on building a certain level of wealth and its associated income stream, playing it safe can mean that you not only fail to grow your funds but may lag behind inflation. By safely avoiding exposure to nature, you may avoid infections in the short term but at the expense of weakening your immune system in the long term.
All new technologies bring both risks and downsides. In most cases, we readily recognize the greater upsides and opportunities. Artificial intelligence is being treated primarily as a massive, catastrophic, existential risk. We hear relatively little consideration of the potentially enormous opportunities for upside gains. Those advancing the AI doom scenarios tell us that this is because “this time it really is different.” This assumes what is to be proved. (I cut a discussion of this point and put it in a separate post.)
Yes, if you are genuinely convinced that the odds of AI destroying humanity are high, you will not care much about what you are giving up by blocking AI progress. It may be that no arguments can shift the AI doomers. In fact, that seems to be the case. But we must keep trying. Even if the doomers won’t revise their thinking, more moderate AI worriers might shift their position enough to keep AI advances going.
[By the way, my use of the term “AI doomer” is not intended to be a sneer, insult, or dismissal. I use it as an apt description of the beliefs of those who are sure the chances of an existentially bad outcome from AI is very high. For those with lower degrees of concern about AI risk, I may use the term “AI worrier”. I admit to having used “AI panicker” but will do my best to refrain from doing so in future.]
Existential opportunity
Every opportunity involves risk. Every risk involves opportunities. Risk implies both a downside and an upside. In the AI discussion, 99% of the emphasis is on the downside. This needs to be rebalanced.
“Existential” risk connotes just the downside, even though that is not the denotational meaning. An existential risk is also an existential opportunity. Talking only of risk obscures this crucial fact and distorts thinking and judgment. Human beings, especially in our culture, tend to focus on the risks and downsides of non-individual action. Framing matters. For this reason, I propose that we use the term “existential opportunity” whenever we talk about existential risk.
I’m going to define the term as follows:
Existential opportunity: An event or series of connected events that can drastically, broadly, and enduringly improve the future of humankind.
In the process of writing this essay, I discovered some prior uses of the term “existential opportunity.” One of them is used quite differently. The other by J. N. Nielsen is quite similar.
Matching existential risk and opportunity helps us bear in mind that a restrictive action taken out of concern for existential risk could itself become an existential risk. It could do that by reducing our capacity to ward off another existential risk. It could do it by pushing risk aversion to the point of stagnation. Our goal should be to reduce existential risks while increasing – or at least not reducing – existential opportunities.
I have also written on a similar theme in considering the paradox of the precautionary principle. I will add that to this blog or include it in my forthcoming collection.
How does “existential opportunity” differ from the existing terms “existential hope” and “existential eucatastrophe”?
Existential eucatastrophe: An existential eucatastrophe is an event which causes there to be much more expected value after the event than before.
That definition comes from a 2015 paper by Owen Cotton-Barratt and Toby Ord. This has weaknesses – “much more” is a bit weak for the kind of thing we’re talking about. Even so, I like it a lot more than the definition in Wikipedia: “A eucatastrophe is a sudden turn of events in a story which ensures that the protagonist does not meet some terrible, impending, and very plausible and probable doom.” There’s nothing wrong with that definition, given that it is true to its origin in the work of J.R.R. Tolkien. Tolkien himself offered the examples of the incarnation of Christ and the resurrection.
Tolkeingateway defines the term as: “A eucatastrophe is a massive turn in fortune from a seemingly unconquerable situation to an unforeseen victory, usually brought by grace rather than heroic effort.” For our purposes, I dislike this definition because it emphasizes an outside force bringing us victory. Even the first definition isn’t ideal because it refers solely to “an event”. By contrast, existential opportunity is more open to a single event or a series of related events or a process. To most ears, I feel safe in saying that “eucatastrophe” just sounds odd.
The passivity problem is also the issue I have with “existential hope.”
Existential hope: “The chance of something extremely good happening.”
This also seems to imply a single event. No doubt “hope” has different connotations depending on who you ask. To me, it exudes passivity and helplessness. “Let’s hope something good happens.” In religious contexts, it is a passive hope that we will be saved by the grace of God. It doesn’t have to mean this. In Star Wars: A New Hope, we don’t come away with the belief that the Empire will go away without hard work by the Rebels. Even so, I find it hard to detach hope from a connotation of passivity and helplessness. By contrast, opportunity clearly indicates that a good outcome is possible, but opportunities must be seized and realized.
Before I make the value of existential opportunity more concrete and vivid, first a quick sidestep to on risk and uncertainty.
Existential uncertainty
I have a technical quibble with the term “risk” in this context, but the quibble also has practical implications.
Rather than existential risk, two reasons suggest that it would be better if we talked about existential uncertainty. Risk more strongly implies dangers and downsides. Uncertainty conveys more balanced implications. An uncertain outcome could just as likely be positive as negative. Cynically, one might think that this is precisely why risk was chosen instead of uncertainty. By more clearly implying both positives and negatives, uncertainty would get less attention by being less alarming.
The other reason is a technical distinction between risk and uncertainty. This distinction was made by economist Frank Knight.
To preserve the distinction which has been drawn in the last chapter between the measurable uncertainty and an unmeasurable one we may use the term “risk” to designate the former and the term “uncertainty” for the latter.
The practical difference between the two categories, risk and uncertainty, is that in the former the distribution of the outcome in a group of instances is known (either through calculation a priori or from statistics of past experience), while in the case of uncertainty this is not true, the reason being in general that it is impossible to form a group of instances, because the situation dealt with is in a high degree unique.
Frank Knight, Risk, Uncertainty, and Profit, Chapter VIII, Structures and Methods for Meeting Uncertainty.
With risks, you can look before you leap. With uncertainty, you have to look while leaping.
Existential risk and opportunity are not just about quantifiable risk but also about unquantifiable uncertainty. To the extent that risk can be quantified, it can be controlled. Use of the term “existential risk” can therefore suggest a clear course of mitigating action. Existential uncertainty cannot be quantified or calculated. This doesn’t mean you can do nothing about it. You keep your eyes open, develop and maintain a flexible response capability and tackle problems as they arise. When we are dealing with uncertainty rather than risk, specific measures prepared in advance will be fruitless, a waste of resources, and quite possibly cause additional problems by forcing a fixed solution to a novel problem.
With risks, you can look before you leap. With uncertainty, you have to look while leaping.
This is one reason why centralized regulation by a government agency is problematic. This kind of regulation can help with risk – in principle though usually not in practice – but is pointless, burdensome, and problematic when it comes to uncertainty.
The AI existential risk debate is really more about uncertainty than about risk. Some of the nearer term risks may be somewhat amenable to risk calculation but existential risk or uncertainty involves too many unknowns and unknown unknowns. This is why I find it silly when people say that the odds of AI doom are 20%, or 50%, or 90%. On what do they base these probabilities?
Giving specific probabilities to highly uncertain events is a symptom of the problematic kind of rationalism that’s been giving rationalism a bad name – the belief or implied belief that future events can always be calculated in terms of probability. I understand that it’s very tempting to calculate probabilities. Despite what I just said, I’m going to come dangerously close to doing it myself! However, I will be emphasizing the ridiculousness of the numbers. The calculation process I will use is helpful for revealing constraints on intuitive probabilities.
Grasping the existential opportunity
What is the cost of stopping or slowing AI progress? (I’d like to call this the opportunity cost but that term is already defined differently in economics.) Due to uncertainty, we cannot know that precisely. Given that the doomers agree with the progressors (sustainers?) that AI is likely to be an immensely powerful technology, we can foresee some of the likely benefits foregone.
Chance of solving the aging problem in time for people 50+ without AI: 10%
Chance of AI solving the aging problem in time for people 50+: 80%
Difference = 70%
With around 1.9 billion humans age 50+, the difference is 1.9 billion x 0.7 = 1.33 billion.
If we expand the group to people who are 30+, the chances of solving aging without AI goes up a little, but so does the chance of solving it with AI (even more so). Let’s assume the same difference of 70%.
With around 4 billion humans aged 30+, the difference is 4 x 0.7 = 2.8 billion.
If life span stretches to 300 or 400 after aging is solved (very conservatively), the number of years of life gained for 4 billion humans will be around a trillion.
If life span stretches to 300 or 400 after aging is solved (very conservatively), the number of years of life gained for 4 billion humans will be around a trillion.
If an extra year of life is valued at $100,000 (a number in today’s range but presumably AI-boosted productivity would raise that number), the value gained would be in the hundreds of quadrillions.
The exact probabilities shouldn’t be taken seriously. Plug in your own assumptions. Within a very wide range, the point is the same – there is an enormous difference in lives saved in a scenario where AI works on the problem and a scenario where it does not. It amounts to a global and terminal loss (to use Bostrom’s term from Global Catastrophic Risks),
If they are wrong, those who stop AI progress are responsible for many billions of deaths and a trillion life years.
AI doomers, certain in their beliefs, yell at us to think of the vastness of the catastrophe if AI goes bad. AI progressors can point out that, if they are wrong, those who stop AI progress are responsible for many billions of deaths and a trillion life years. These are not theoretical, non-existent people of the future. They are actual people, living now.
And this doesn’t even account for the potential for great improvements in human well-being as wealth explodes and physical and mental pathologies are cured. Nor have I mentioned the threat of China or other dangerous actors dominating if they are allowed to take the lead.
More gains from letting AI rip
Vastly more years of life is probably the biggest existential opportunity. But let’s bring it down to some specifics, especially for those who think AI will be godlike but somehow unable to cure aging.
AI can improve intelligence in just about all industries. Everything can be improved with more embedded intelligence. AI, whether in the current form of machine learning or some new paradigm yet to emerge, looks set to become the most general purpose technology of our time. It will improve workplace safety, avoid accidents, improve educational opportunities, improve financial services, power the Internet of Things, improve entertainment, aviation, the automotive industry, climate management, and more. If allowed, it could vastly improve economic and political decision making by presenting and explaining solutions that politicians and interest groups will be hard pressed to ignore.
Marc Andreesen offers a list of beneficial uses that we can reasonably expect:
Personal tutor for every child
AI assistant/coach/trainer/advisor/therapist
Every scientist will have an AI assistant/collaborator/partner
Leaders of all kinds will have decision assistants
Massive productivity growth, boosting economic growth, new industries, new jobs, wage growth
Scientific breakthroughs and new technologies and medicines will dramatically expand
The creative arts will enter a golden age
Improve warfare, when it has to happen, by reducing wartime death rates dramatically
Hard to believe, but machine learning might even fix the news.
In one of his many excellent papers on AI and regulation, Adam Thierer includes a section on AI’s potential for medicine and health care:
Heart attack detection and treatment
Cancers
Sepsis and superbugs
Paralysis
Mental health and drug addiction
AI is already improving these areas:
Organ donation
Already better at assessing risk for breast cancer
Diagnosis – already helping with heart and eye conditions, sepsis risk, chest x-ray detection, ultrasounds
Algorithmic technologies will enable doctors and researchers to access the vast and rapidly growing among of patient and health data.
You will find many health and other benefits collected here, with links to more information.
Here’s a blog that keep tracks of efforts to use AI in biomedical settings.
A culture of fear and excessive caution is combining with an ever-growing burden of regulation and control, falling productivity, and the growing force of depopulation.
Taking a wider and longer view, our economies are sliding gradually into stagnation. This itself is an existential risk. A culture of fear and excessive caution is combining with an ever-growing burden of regulation and control, falling productivity, and the growing force of depopulation. As population shrinks, there will be fewer (and older) minds working on solving problems and creating benefits. AI is our best chance to reignite and accelerate progress.
Obstacles to AI doom
I have emphasized the massive benefits possible and likely from AI advancing. I have pointed out the existential risks of not proceeding. What about the other side of the scale? How likely is AI doom?
This section could be its own essay or a series of essays. This essay is already long enough so I want only to gesture at an approach to evaluating AI risks that I think helps us to see that they are lower than some would have us believe. It’s beyond my scope here to respond to the huge number of specific doom scenarios (such as this one from Holden Karnofsky), and I will only briefly note some of the factors that make deadly AI less likely.
I have made more salient the potentially massive upsides to AI from the grand (saving billions of lives) to the everyday. AI doomers are asking or demanding that we forego all of these huge upsides for the theoretical possibility that AI might take over and there will be no more humans.
That’s not unreasonable if the changes of doom or existential calamity really are high. For people to open up to existential opportunities, they must first relinquish certainty of belief in very high odds of catastrophe. Speculative stories of how AI might take over can be compelling. To better evaluate how likely they are – or any other story of AI doom – it helps to identify the obstacles in the way of such an outcome.
One way to do this is to create an AI risk equation modeling on the famous Drake equation. The Drake equation identifies seven factors that should shape our estimation of the number of active, extraterrestrial civilizations that might communicate with us. Given the wide range of estimates for each factor, the Drake equation does not solve the problem but helps us identify which factors we need to focus on when thinking about the probability of life beyond Earth. Drake listed factors such as the mean rate of star formation, fraction of stars that have planets, fraction of planets with life where life develops intelligence, and so on.
Few of the probability factors in the Drake equation can be based on observation, so results are all over the map. Where the equation does help is in directing attention and study to the areas of great uncertainty, perhaps eventually narrowing the range of plausible results. An AI risk equation also contains much uncertainty but is more down to earth. Again, even if we distrust the results of a calculation, it can help illuminate the factors that need clarifying and perhaps rule out some extremes.
One such AI risk equation has been developed by Jon Evans. His equation consists of seven elements:
Pₘ = probability of making an AGI.
Pₐ = probability of not developing working alignment (i.e. control) of AGI.
Pₛ = probability of the AGI even wanting to be smarter.
Pₙ = probability of the AGI having access to the resources necessary to maximize its own intelligence
Pₜ = probability of intelligence maximization being uninterruptible, which means, in practice, some combination of" fast" and "inobtrusive" — if very fast it doesn't necessarily need to be inobtrusive, if very inobtrusive it doesn't necessarily need to be fast.
Pₒ= probability of an intelligence-maximization feedback loop remaining continuously effective until a sufficiently advanced superintelligence is attained. “Sufficiently” – creatures with physical or environmental advantages often win over much more intelligent creatures.
Pₕ = probability of that sufficiently advanced superintelligence deciding to end humanity.
Multiplied together, these give you: Pₓ = probability of a superintelligent AI going Skynet and exterminating us all. What is his result? Jon says: “Getting back to the equation and picking what seems to me a very pessimistic set of numbers for 2050, .5 x .9 x .8 x .5 x .6 x .2 x .6, we get roughly a 1% chance of catastrophe.” He follows up with an important caveat (emphasis added):
This is a meaningless number and of course you should not lend it any credence. But I want to use it to point out that if you only look at the first two terms — the chance of developing AGI, and the chance of it not being aligned — catastrophe seems 35 times more likely! If you assume an unaligned AGI will automatically think itself into a homicidal superintelligence, then of course you’re worried. But, again, that seems an awfully crude belief.
Annoyed with the high-confidence AI doomers, he adds:
Given all the above, the belief that immediately after we create an alien, it necessarily can and will promptly bootstrap itself into a god ... a pretty reasonable description for any entity which can casually exterminate humanity and/or render the Earth into gray-goo cheese ... seems not merely religious but faintly ridiculously so. I mean. Maybe? I concede we can't absolutely rule it out? But the people who believe this sure seem weirdly certain about it.
Rohit Krishnan developed his own version which he calls the AGI Strange Loop Equation.

Scary AI = I * A1 * A2 * U1 * U2 * A3 * S * D * F
Probability of real intelligence
Probability of being agentic
Probability of having ability to act in the world
Probability of being uncontrollable
Probability of being unique
Probability of having alien morality
Probability that AI is self-improving
Probability the AI is deceptive
Assigning probabilities of 80%, 50%, 60%, 80%, 25%, 10%, 25%, 80%, and 15%, he gets the result of 0.0144%. He provides an online spreadsheet so you can plug in your own estimates.
There will be objections about the independence of the variables. Rohit discusses this in his essay and in the comments.
As AI develops, so will our capabilities to respond.
One limitation of this probability calculation approach is that it assigns static probabilities to each item. In reality, as AI develops, so will our capabilities to respond. That consideration becomes especially important when we think about how to restrict and what kinds of restrictions to impose. Rohit makes a similar point: “I still think there’s an insane amount of Knightian uncertainty in the ways in which this is likely to evolve. I also think there’s almost no chance that this will get solved without direct iterative messing about with the tools as they’re built.”
I started constructing my own risk equation but let it go because I wasn’t happy with it. Refining to a point where I would prefer it over Jon’s and Rohit’s would indefinitely delay this essay. Some of my factors arguably overlap with theirs but may contain constraining factors that their equations do not. Jon’s Pₜ refers to unobtrusiveness whereas Rohit’s does not. Mine included two places where secrecy or the ability to hide from detection by humans played a role.
I think that “having ability to act in the world” is insufficiently strong as a condition. Having the ability to do a lot of work in the physical world is a big factor. Some, such as Karnofsky, argue that this is not necessary but I’m not at all convinced that his brain in a box would be able to take over. It might be able to kill everyone but would then itself perish for lack of energy.
Again, I’m not going to attempt to argue in detail for the probability of any of the items in these equations – or checklists if you prefer to take that way. Instead, I’m only going to briefly note what I think are some of the greater obstacles to AI-as-Cthulhu.

Image by Hrairoo via Midjourney
It is typically assumed that AI will rapidly move from human level intelligence to superhuman level through recursive self-improvement. Rapid bootstrapping will not only add processing power and memory but also improve the way AI works. When I expressed my doubts about this back in the 1990s to Vernor Vinge, he looked surprised. He had often heard people dismissing the idea of human level AI but not the view that, if achieved, AGI would rapidly widen the distance between them and us. More recently, I’ve noticed a more people challenging this assumption. For instance, Vitalik Buterin said:
If I had to predict a concrete place the AI doomer story is wrong, if it had to be wrong, I would say it’s in the idea of a fast take-off: that AI capabilities will pile on so fast that we won’t be able to adapt to problems as they come. We may well have a surprisingly long period of approximately human-level AI.
Without a rapid takeoff (“foom”), handling AI looks much more workable.
Recently, on the blog of Scott Alexander (perhaps an AI worrier but not quite a doomer in my taxonomy), in someone’s review of Why Machines Will Never Rule the World, the writer acknowledged doubts about the assumption that AI would become superhumanly intelligent and then rapidly ever more intelligent:
But I do think there’s something to the complexity and computability arguments. What level of innovation is required to create a general intelligence of the Skynet-and-Matrix-manifesting kind? Is it just a matter of scaling up current methods and hardware? Do we need new algorithms? New paradigms? Mathematical innovations as revolutionary as the differential calculus? Wetware? Hypercomputation?
In physics, exponential curves always turn out to be S-shaped when you zoom out far enough. I’m not sure anyone’s in a position to say when we’ll reach the upper elbow of the current deep-learning-fueled boom. Moore’s law isn’t quite dead, but it’s dying. The Landauer limit seems near and the ARC tasks far. And even if we can create general intelligence in silico, many of Landgrebe and Smith’s points apply doubly to recursive, Singularity-like scenarios.
I suspect that the “alignment problem” will turn out to be something different than is being discussed and more tractable. One issue is that it has been assumed that we will never understand what’s going on inside machine learning systems (the black box problem). But we have already seen progress in this area. Even AI Doomer Prime, Eliezer Yudkowsky acknowledged that this was a pleasant surprise and slightly modified his p(doom).
Compared to the usual AI doom scenarios, I would assign a much greater risk to humans using AI as a tool to control other humans or otherwise dominate them or destroy them. It might be less likely to be an extinction outcome but more likely to be a really bad outcome
In the end, I’m willing to tolerate a significant possibility of AI doom in return for the larger possibility of massive gains in human life span and wellbeing. At the same time, I favor a continual effort to pay close attention to possible emerging dangers and deal with them quickly. Measures should get more restrictive if we have more real evidence of serious problems. I do not believe that the situation today warrants drastic restrictive measures. If I see AI designing and releasing deadly pathogens, deciding on their own to attempt to take control of military systems, or a rapid and unexplained increase in energy consumption not traceable to human activities, I will shift toward a more precautionary stance.
But look at what the experts believe!
But don’t surveys show that AI researchers think there is a 20% chance of doom? Probably not. Even if that were the case, AI researchers are not the only people with relevant expertise since AI risks involve other than the details of AI programming or training.
Precautionary and centralized is not the way
The common response both to more immediate concerns about bias, spam, and cheating and to existential risk fears is a call for regulation of AI. Typically, proposals are based on the precautionary principle, consciously and explicitly or not. They usually call for a new regulatory agency and top-down regulation of all AI applications.
Regulatory approaches embodying the precautionary principle position use of AI as “unlawfulness by default”, as two law two law professors put it. You can see the precautionary stance in their language: “We propose a presumption of unlawfulness for high-risk models, while the AI developers should have the burden of proof to justify why the AI is not illegitimate.” In 2017, the European Parliament adopted this resolution, requiring that research and commercialization of AI and robotics “should be conducted in accordance with the precautionary principle...” This approach essentially makes new algorithmic technologies illegal until and unless a bureaucratic eventually allows it.
But we must have some regulation of AI! Not enough effort is being put into this! So you may say. I have to wonder why we need yet another regulatory agency devoted to AI. We already have over 2.1 million federal government civilian employees, in 15 Cabinet agencies, 50 independent federal commissions, and over 430 federal departments. Gary Marchant and his team at Arizona State University College of Law did the hard work of adding up the number of official AI efforts currently underway. Just in the time between 2016 and 2019, they identified 634 proposed governance frameworks by academic groups, NGOs and various companies and major trade associations. How much has that number multiplied in the following three years?
No, it’s not true that little attention is being paid to controlling AI. The last thing we need is a new regulatory agency, ripe for capture by special interests and incentivized to be overly cautious and heedless of the benefits of innovation. Existing agencies have already been developing policies suited to their areas of responsibility, including the FTC, the Food and Drug Administration, the National Highway Traffic Safety Administration, the Federal Aviation Administration, the Equal Employment Opportunity Commission and the Consumer Product Safety Commission. Courts and common law are also ready to deal with emerging problems.
I have detailed problems with the precautionary principle in previous essays. Others have contrasted the problematic precautionary principle with the Proactionary Principle or “permissionless innovation”, such as Adam Thierer and Daniel Castro & Michael McLaughlin.
Forbidding trial and error, precautionary regulation reduces learning and reduces the benefits that could have been realized.
Regulations based on the precautionary principle block any innovation until it can be proved safe. Innovations are seen as guilty until proven innocent. Since we cannot foresee all outcomes, good or bad, this requirement is impossible to meet. In practice, exceptions will be made according to political and bureaucratic motives. Implicit in this approach is the assumption that we can figure out all problems beforehand. As Adam Thierer put it, AI critics apparently want to catalog everything that could go wrong, echoing a 2005 parody from The Onion: “Everything That Can Go Wrong Listed.”
The precautionary principle fails to recognize that we need experimentation to uncover failures and problems and figure out how to correct them. Forbidding trial and error, precautionary regulation reduces learning and reduces the benefits that could have been realized – what scientist Martin Rees referred to as “the hidden cost of saying no.”
Proactionary safety
If the precautionary principle suppresses innovation, slows economic growth and social progress, and is subject to regulatory capture, what is the alternative? Some AI doomers are fully aware of the baneful effects of this principle and oppose it in other situations. Given their certainty in a cataclysmic outcome, in this unique case the progress-blocking effect is a selling point for the precautionary principle. Many of them will grant that, for just about anything else, the Proactionary Principle provides a far better approach.
Eliezer Yudkowsky once told me (around 20 years ago) that the Proactionary Principle “doesn’t cut the mustard.” Once you understand the Principle, you can see that he was mistaken.
In one short-form version, the Proactionary Principle says to: “Protect the freedom to innovate and progress while thinking and planning intelligently for collateral effects. In making decisions about innovative technologies, it suggests five main guidelines:
Be Objective and Comprehensive
Prioritize Natural and Human Risks
Embrace Diverse Input
Make Response and Restitution Proportionate
Revisit and Revise
If you read the details of the ProP (for short), it will be obvious that it does not predetermine the outcome. It does have a healthy tilt toward innovation, but it emphasizes different levels of response depending on severity, scope, and endurance of bad effects. The ProP includes caution. It keeps caution in perspective, balancing it with the effects of excessive caution. It stresses a proportionate response. What counts as excessive clearly depends on the situation. For instance, it seems highly likely that the proactionary framework will lead to more restrictive policies for AI applications like autonomous military technology.
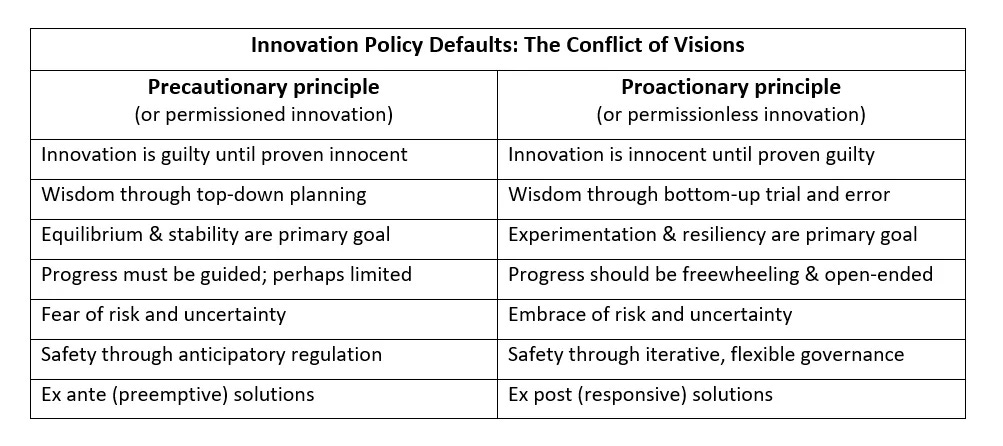
From: https://medium.com/@AdamThierer/the-proper-governance-default-for-ai-d05db6970924
Discussing the Proactionary Principle, Adam Thierer notes:
There are different names for this same concept, including the innovation principle, which Daniel Castro and Michael McLaughlin of the Information Technology and Innovation Foundation say represents the belief that “the vast majority of new innovations are beneficial and pose little risk, so government should encourage them. Permissionless innovation is another name for the same idea. Permissionless innovation refers to the idea that experimentation with new technologies and business models should generally be permitted by default.
Adam suggests that we not default to a precautionary principle and instead favor a policy approach that:
(1) objectively evaluates the concerns raised about AI systems and applications
(2) considers whether more flexible governance approaches might be available to address them
(3) does so without resorting to the precautionary principle as a first-order response
The Proactionary Principle, Adam says, is a better general policy default because it satisfies these three objectives.
The proactionary principle is the better general policy default for AI because it satisfies these three objectives.[24] Philosopher Max More defines the proactionary principle as the idea that policymakers should, “protect the freedom to innovate and progress while thinking and planning intelligently for collateral effects.”[25]
To my surprise, as I was writing this piece, Google came out with a new AI policy that looks miles better than proposals in the EU and the USA to date. Ron Bailey, covering it here, explains how Google’s approach differs from the “ill-advised centralized, top-down licensing scheme suggested by executives at rival A.I. developers OpenAI and Microsoft”, instead recommending a decentralized “hub-and-spoke model" of national A.I. regulation.” Rather than a new “Department of AI”, AI tools should be evaluated in their context of use and, in the Google’s policy’s words, “use existing authorities to expedite governance and align AI and traditional rules” and provide, as needed, “updates clarifying how existing authorities apply to the use of AI systems.”
Here a few measures that make sense to me, both for current concerns and for the truly devastating possibilities that do not yet exist:
Hold creators and users of AI accountable, using existing liability (including product recall), common law remedies, property and contract law (clarified as needed), and insurance and other accident-compensation mechanisms. This might include requiring all AI output to be labeled as such and with denotation of the system originating the output.
Monitor AI systems with other AI systems. Encourage and sustain a polycentric network of AIs with none able to dominate the others. Incentive AIs to check on each other.
To the extent that government regulatory agencies are politically unavoidable), avoid a new, single entity and instead use domain-specific agencies such as NIST (which already has a A.I. Risk Management Framework), and agencies already overseeing medical devices, educational institutions, transportation, and so on. Also use federal and state consumer protection statutes and agencies.
Don’t connect powerful general purpose AI to nuclear weapons, jet fighters, power stations, robot factories, or major financial systems. Outside of SF, chatbots are not deadly but AI connected to powerful physical systems could be.
Favor more special purpose AI over general capability AI (or AI over AGI). The more general the capabilities of an AI, the less it should have direct access to critical physical resources.
If you are using AI to run physical tools and systems, make those systems physically isolated and run by narrow AI and able to be shut down.
Avoid giving AI strong agency and desires. Continuing developing training, feedback, and alignment methods.
Be reasonably transparent about how your AI works. Do not support organizations that will not do this. I say “reasonably transparent” because too much transparency makes it somewhat easier for other countries to copy the AI system. If not transparent, each AI should be identifiable so that responsibility can be assigned.
Focus on intelligence augmentation (IA) at least as much as AI.
[After creating the above list, I read a draft of a proposal by David Brin which I found very compatible. I tweaked a couple of items to emphasize accountability more clearly.]
There will be other, more technical and specific methods, but those are for others to propose. They will change with conditions but the foregoing approaches should be more generally and enduringly applicable.
Above, I mentioned an argument for a doom scenario by Holden Karnofsky. He has also very recently suggested a playbook (not a plan) for reducing AI risk. This kind of solution-oriented thinking is helpful.
A pure proactionary approach is not a zero-precaution approach.
Government policy could end up anywhere between the precautionary/permissioned and proactionary/permissionless positions. The more elements taken from the proactionary approach, the better. Remember, a pure proactionary approach is not a zero-precaution approach. It involves using the best methods to take reasonable and proportionate protective measures and not to overreact or suffocate technology with outdated, compulsory constraints.
In another excellent piece by Adam Thierer from 2017, he provides “three reforms to protect permissionless innovation.” Policy reforms should be based on three ideas
The Innovator’s Presumption: Any person or party (including a regulatory authority) who opposes a new technology or service shall have the burden to demonstrate that such proposal is inconsistent with the public interest.
The Sunsetting Imperative: Any existing or newly imposed technology regulation should include a provision sunsetting the law or regulation within two years.
The Parity Provision: Any operator offering a similarly situated product or service should be regulated no more stringently than its least regulated competitor.
You will find my previous discussion of the current topic in these blog posts.
Against AI doomerism, for AI Progress
Gary Marcus’ AI Regulation Error
In the end, the choice comes down to cowering in the face of fear of possible AI doom or seizing the existential opportunity to move ahead with the right mix of boldness and protection. The opposite poles that define that basic underlying attitudes were memorably expressed in H.G. Wells’ 1933 novel, The Shape of Things to Come. There’s a lot wrong with other parts of Wells’ vision, but this part resonates:
Raymond Passworthy: Oh, God, is there ever to be any age of happiness? Is there never to be any rest?
Oswald Cabal: Rest enough for the individual man -- too much, and too soon -- and we call it death. But for Man, no rest and no ending. He must go on, conquest beyond conquest. First this little planet with its winds and ways, and then all the laws of mind and matter that restrain him. Then the planets about him and at last out across immensity to the stars. And when he has conquered all the deeps of space and all the mysteries of time, still he will be beginning.
Raymond Passworthy: But... we're such little creatures. Poor humanity's so fragile, so weak. Little... little animals.
Oswald Cabal: Little animals. If we're no more than animals, we must snatch each little scrap of happiness and live and suffer and pass, mattering no more than all the other animals do or have done. Is it this? Or that? All the universe? Or nothingness? Which shall it be, Passworthy? Which shall it be?
Hey Max,
In a rare case of algorithms getting something right, Notes threw this piece up at me and I've decided - with some trepidation - to comment. The cause of this nervousness is simply that the other Max typically encounters my comments as a fly in his primordial soup, and I rather suspect you will too. Nonetheless, here I am! And let me say, I am commenting in part out of respect to your anarchist roots, since I usually don't want to talk to people working in your general space for reasons that will become clear. But Michael Moorcock has been central to my philosophical development, and as such I have great respect for anyone grappling with the problems of anarchy. It calls me and I resist; it is practically my life's story.
Prologue aside, I find this entire essay akin to a stone that skims across the water and never goes in - there's a joy to that, but it misses the satisfying 'plop'. Let me preface any further remarks by saying that my background is in AI - my Masters degree was in this field, although by PhD I had veered into philosophy, where I remain, and remain (as I like to say) an 'outsider philosopher'. I say this not to puff up my feathers, but to explain where I am coming from as I feel it relevant to understanding what I have to say that I am a heretic who fled the clerisy.
On your downplaying of existential risks, I concur - sort of. I mean, the existential risks are more absurd than you seem to think, but you are wise to deflate in this regard. Current AI is still built on the same bag of tricks I studied in the 90s, the sole differences are the improvements in computing power, the availability of vast quantities of human data to train the neural networks, and the plumbing to get more variety out the other side. I remain, as I did then, woefully under impressed with this fuss over AI. We certainly may destroy ourselves with our technology (in a sense, we already have, but let's leave that tangent aside) but there is no risk here greater than the one we already shouldered with nuclear weapons, and the illusion that there is depends upon overhyping the difference between (actual) AI systems and (imaginary) 'Artificial General Intelligence', or 'super-robots'.
The true risk with current AI is not existential at all, at least in the sense of extinction. It is political and social. We already exist on the edge of political catastrophe, or perhaps have fallen off that edge, and the transplanting of discourse into social media represents one of the greatest political threats of our time. The danger of AI is in turbo-charging censorship even further than it has already been driven by the US federal agencies such as the CISA (the absurdly titled Cybersecurity Infrastructure Security Agency - because one 'security' is never enough when you are playing in the totalitarian toolbox!). AI already successfully silences what is unwelcome by the ruling powers, which has put the sciences deep into the state of pseudoscience where the engine of validation fails and all that is left is commercial opportunism. This is the most plausible risk of AI: the entire control of social narrative in a world where all discourse is online, along with the termination of scientific practice.
Hence, indeed, calls for regulation. I don't know how much of this is naivety (the great houses and guilds of today have no shortage of it) and how much of this is gentle pushing by enthusiastic spooks, but inevitably (as you seem to correctly intuit) we're hearing calls for regulation that amount to monopolising AI for State and commercial benefits - primarily censorship. The good news in this regard is that this cannot entirely succeed for the same reason that 'the black library' (torrent file-sharing) could be pressured but not eliminated (good news for cypherpunks, too!). The trouble with technological regulation right now, anyway, is that there is no framework by which it can be pursued, because none of the contemporary empires have any interest in co-operation. So talk of regulation can only be calls for building new monopolies on old monopolies. Hard pass.
The strange turn in your thinking - which is not strange to you, because of your faith in technology I suspect - is that you suggest that what AI can bring us is the toolkit to extend life, which you view as eucatastrophic in the non-Tolkien sense. But life extension is merely catastrophic, there's nothing good here except the fantasy. I doubt I will persuade you, since you are committed to this path, but what could be worse at this point than extending the lives of the wealthy (the proximate consequence of such tech) except perhaps extending the lives of everyone...? If you wouldn't call for raising the birth rate by an order of magnitude, you cannot reasonably support collapsing the death rate by an order of magnitude either. Maybe you've already written on this - if so, a link is welcome rebuttal!
Everyone who inhabits this fictionality surrounding life extension has to wobble around the trade off i.e. that life extension must come at the sacrifice of births - and what do you think the regulation of this would look like...? I am unconvinced by the 'I'd gladly trade longer life for no kids' crowd, because I see a nest of vipers along this path if it works on the honour system and something far worth if governments get their claws into it. Honestly, I don't quite understand why death has got such a bad rep in the technocratic paradigm except that we traded the old mythologies for new ones and never gained the insight into them that the mid-twentieth century philosophers foolishly believed we had gained. We didn't. Perhaps we never will.
The good news (for me, for your side it is bad news I'm afraid) is that the problems required to solve in extending life are not ones that can be addressed solely by throwing AI into the gap. Just as the 'mapping of the human genome' was an excellent boondoggle for those selling gene sequencers with next to zero benefits to anyone else, AI can do zip with any amount of genetic data, because we haven't even come close to building a 'genetic computer'. Genetic 'code' is not analogous to computer code at all (except in the metaphorical sense of 'hacking', which is accurate to what we can do with it). Most likely way of extending life expectancy within the next few centuries is creating cold-blooded humans (literally, we already have the metaphorical kind), but this would have to be inflicted at birth, and would come with the lifestyle modifications associated, and quite possibly a massive step down in intellectual prowess (as if we weren't already dealing with this...).
So alas, here I am, most likely as a gadfly where I am not welcome. Evidently, I am a technological deflationist - no-one is more surprised at this than I, I assure you! I gorged on sci-fi in my youth and one does not take a Masters in AI to pop balloons. But once you've been to the factory, you are no longer tempted to drink the Koolade because you've seen what it is made from (which is literally true, by the way, as well as being metaphorically true).
Because this feels like the right thing to do in conclusion, let me leave you with a link for one of June's Stranger Worlds. These are only 750 words (3-minute read), and thus shorter than this comment(!). It captures rather well how I feel about both AI and imaginary super-AI:
https://strangerworlds.substack.com/p/laws-of-robotics
It is also, I suppose, an invitation.
With unlimited love and respect,
Chris.
I do hope you are correct: I suspect strong AI is a prerequisite to my being successfully revived from cryonic suspension. I firmly agree with everything you say about the benefits that will accrue if we can just get it right, and the hugeness of the missed opportunity if we decide the risk is too great but are mistaken.
But S-curves notwithstanding, I see no reason to believe that human-level intelligence is as high as you can go. And you can ask the Neanderthals or Homo Erectus how well it works to have somebody around who is smarter. Or you could, if they were still here. So I’m gonna stay worried.